1.图的基本概念、名词术语;
2.图的邻接矩阵存储方法和邻接表(含逆邻接表)存储方法的构造原理及特点;
3.图的深度优先搜索与广度优先搜索;
4.最小(代价)生成树、最短路径、AOV网与拓扑排序的基本概念。
1.图的基本概念、名词术语;
1.1 图的定义
图是由顶点的非空有穷集合与顶点之间关系(边或弧)的集合构成的结构,通常表示为 G =(V,E)
其中,V 为顶点集合,E 为关系(边或弧)的集合。
1.2 图的分类
- 无向图:对于 $(v_i,v_j) \in E$,必有 $(v_j,v_i) \in E$,并且偶对中顶点的前后顺序无关。
- 有向图:若 $\langle v_i,v_j \rangle \in E$ 是顶点的有序偶对。
- 网络:与边有关的数据称为权,边上带权的图称为网络。
1.3 名词术语
- 顶点的度:依附于顶点 $v_i$ 的边的数目,记为 $TD(v_i)$。
- 对于有向图,有 出度、入度:
- 顶点的出度:以顶点 $v_i$ 为出发点的边的数目,记为 $OD(v_i)$。
- 顶点的入度:以顶点 $v_i$ 为终止点的边的数目,记为 $ID(v_i)$。
- $TD(v_i) = OD(v_i) + ID(v_i)$
- 对于具有 n 个顶点,e 条边的图,有 $2e =\sum_{i=1}^n TD(V_i)$。
- 具有 n 个顶点的无向图最多有 $n(n-1)/2$ 条边。
- 具有 n 个顶点的有向图最多有 $n(n-1)$ 条边。
- 对于有向图,有 出度、入度:
- 路径:顶点 $v_x$ 到 $v_y$ 之间有路径 $P(v_x,v_y)$ 的充分必要条件为:存在顶点序列 $v_x,v_{i1},v_{i2},…,v_{im},v_y$,并且序列中相邻两个顶点构造的顶点偶对分别为图中的一条边。
- 出发点与终止点相同的路径称为 回路 或 环;
- 顶点序列中顶点不重复出现的路径称为 简单路径。
- 不带权的图的路径长度是指路径上所经过的边的数目,带权图的路径长度 是指路径上经过的边上的权值之和。
- 子图:对于图 $G = (V,E)$ 与 $G´ = (V´,E´)$,若有 $V´ \subseteq V,E´ \subseteq E$,则称 $G´$ 为 $G$ 的一个子图。
- 图的连通:
- 无向图的连通:无向图中顶点 $v_i$ 到 $v_j$ 有路径,则称顶点 $v_i$ 与 $v_j$ 是连通的。若无向图中任意两个顶点都连通,则称该无向图是连通的。
- 有向图的连通:若有向图中顶点 $v_i$ 到 $v_j$ 有路径,并且顶点 $v_j$ 到 $v_i$ 也有路径,则称顶点 $v_i$ 与 $v_j$ 是连通的。若有向图中任意两个顶点都连通,则称该有向图是强连通的。
- 生成树:包含具有 n 个顶点的连通图 G 的全部 n 个顶点,仅包含其 n-1 条边的极小连通子图称为 G 的一个生成树。
2.图的邻接矩阵存储方法和邻接表(含逆邻接表)存储方法的构造原理及特点;
对于一个图,需要存储的信息应该包括:
- 所有顶点的数据信息;
- 顶点之间关系(边或弧)的信息;
- 权的信息(对于网络)。
2.1 图的邻接矩阵存储方法
核心思想:利用两个数组存储一个图。
- 一个一维数组 $VERTEX[0...n-1]$ 存放图中所有顶点的数据信息(若顶点信息为 $1,2,3,…$,此数组可略)。
- 定义一个二维数组 $A[0...n-1,0...n-1]$ 存放图中所有顶点之间关系的信息(该数组被称为 邻接矩阵)
- 对于不带权的图, 有: $A[i][j] =\begin{cases} 1, & 当顶点 v_i 到顶点 v_j 有边时 \ 0, & 当顶点 v_i 到顶点 v_j 无边时 \end{cases}$
- 对于带权的图, 有: $A[i][j] =\begin{cases} w_{ij}, & 当顶点 v_i 到顶点 v_j 有边,且边的权为 w_{ij} \ \infty, & 当顶点 v_i 到顶点 v_j 无边时 \end{cases}$
2.1.1 邻接矩阵特点
- 无向图的邻接矩阵一定是一个对称矩阵。
- 不带权的有向图的邻接矩阵一般是稀疏矩阵。
- 无向图的邻接矩阵的第 i 行(或第 i 列)非 0 (或者非 $\infty$ 元素)的个数为第 i 个顶点的度数 $TD(v_i)$。
- 有向图的邻接矩阵的第 i 行非 0 (或者非 $\infty$ 元素)的个数为第 i 个顶点的出度 $OD(v_i)$;第 i 列非 0 (或者非 $\infty$ 元素)的个数为第 i 个顶点的入度 $ID(v_i)$。
2.1.2 邻接矩阵的建立
/* 定义最大值 INF */
#define INF 0xffffff
/* 定义最大顶点个数 */
#define MAXN 100
void CREATE_MAP(int Map[][MAXN], int n, int e) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
Map[i][j] = INF; // 邻接矩阵赋初值
}
}
for (int i = 0; i < e; i++) {
scanf("%d %d %d", &a, &b, &w); // 输入每条边的起始点、终止点和边权值
Map[a][b] = w;
Map[b][a] = w;
}
}- 时间复杂度:$O(n^2+e)$,其中 $O(n^2)$ 的时间耗费在对邻接矩阵的每个分量置初值的操作上。
2.2 图的邻接表存储方法
核心思想:对具有 n个顶点的图建立 n 个线性链表存储该图。
- 每一个链表前面设置一个头结点,用来存放一个顶点的数据信息,称之为顶点结点 。其构造为 vertex | link 。
- 其中,vertex 域存放某个顶点的数据信息;
- link 域存放某个链表中第一个结点的地址。
- n 个头结点之间为一数组结构。
- 第 i 个链表中的每一个链结点(称之为 边结点)表示以第 i 个顶点为出发点的一条边;边结点的构造为 adjvex | weight | next 。
- 其中,next 域为指针域;
- weight 域为权值域(若图不带权,则无此域);
- adjvex 域存放以第 i 个顶点为出发点的一条边的另一端点在头结点数组中的位置。
2.2.1 邻接表特点
- ⽆向图的第 i 个链表中边结点的个数是第 i 个顶点度数。
- 有向图的第 i 个链表中边结点的个数是第 i 个顶点的出度。
- 若图中有 n 个顶点、e 条边,则采用邻接表存储无向图时,需要 n 个顶点结点,2e 个边结点;采用邻接表存储有向图时,需要 n 个顶点结点,e 个边结点。
2.2.2 邻接表的结构定义
typedef int ElemType;
typedef struct Edge { /* 边结点 */
int adjvex; /* 该边的终止顶点在顶点结点中的位置 */
int weight; /* 该边的权值 */
struct Edge *next; /* 指向下一个边结点 */
}ELink;
typedef struct ver { /* 顶点结点 */
ElemType vertex; /* 顶点的数据信息 */
ELink *link; /* 指向第一条边所对应的边结点 */
}VLink;2.2.3 邻接表的建立
void CREATE_LINK_MAP(VLink G[], int n, int e) {
for (int i = 0; i < n; i++) {
G[i].vertex = i+1;
G[i].link = NULL; /* 建立 n 个顶点结点 */
}
int vi,vj,weight;
for (int i = 0; i < e; i++) {
scanf("%d%d%d",&vi, &vj, &weight); /* 输入每条边的起始点、终止点和边权值 */
ELink *p = (ELink *)malloc(sizeof(ELink)); /* 申请一个边结点 */
p->adjvex = vj-1;
p->weight = weight;
p->next = NULL;
if (!G[vi-1].link) { /* 若第 vi 个链表只有头结点 */
G[vi-1].link = p;
} else {
ELink *q = G[vi-1].link;
while (q->next) { /* 找到第 vi 个链表的表尾结点 */
q = q->next;
}
q->next = p; /* 将新结点插入到第 vi 个链表表尾 */
}
}
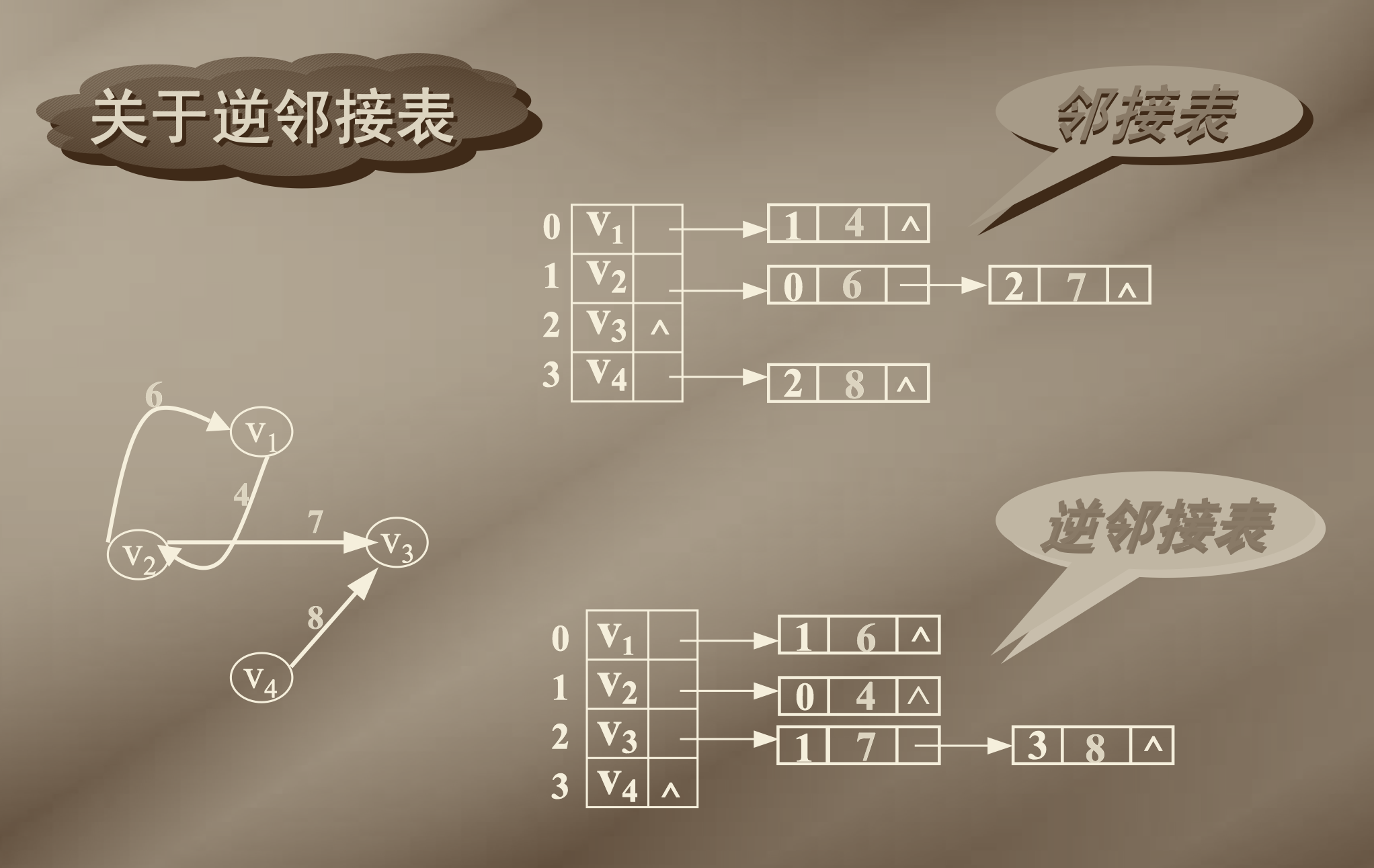
}2.3 图的逆邻接表存储方法
按照建立邻接表的基本思想,对于有向图中的每一个顶点,建立以该顶点为重点(弧头)的一个链表,即把所有以该顶点为终止顶点的边结点链接为一个线性链表。
3.图的深度优先搜索与广度优先搜索;
从图中某个指定的顶点出发,按照某一原则对图中所有顶点都访问一次,得到一个由图中所有顶点组成的序列,这一过程称为 图的遍历。
3.1 图的深度优先搜索
3.1.1 原则
从图中某个指定的顶点 v 出发,先访问顶点 v,然后从顶点 v 未被访问过的一个邻接点出发,继续进行深度优先遍历,直到图中与 v 相通的所有顶点都被访问;若此时图中还有未被访问过的顶点,则从另一个未被访问过的顶点出发重复上述过程,直到遍历全图。
3.1.2 算法分析
如果图中具有 n 个顶点、e 条边,则:
- 若采用邻接表存储该图,由于邻接表中有 2e 个或 e 个边结点,因而扫描边结点的时间为 $O(e)$;而所有顶点都递归访问一次,所以, 算法的时间复杂度为 $O(n+e)$。
- 若采用邻接矩阵存储该图,则查找每一个顶点所依附的所有边的时间复杂度为 $O(n)$,因而算法的时间复杂度为 $O(n^2)$。
3.1.3 算法实现(邻接表结构)
void DFS(VLink G[], int v) {
printf("%d ",G[v].vertex); /* 访问节点 v */
visit[v] = 1; /* 将顶点 v 对应的访问标记置为 1 */
ELink *p = G[v].link; /* p 赋值为顶点 v 的第一个边结点 */
while (p) {
if (visit[p->adjvex] == 0) {
DFS(G, p->adjvex);
}
p = p->next; /* 求顶点 v 的下一个边结点 */
}
}
/* DFS 主算法 */
void TRAVERSE_DFS(VLink G[], int n) {
for (int i = 0; i < n; i++) {
visit[i] = 0; /* 标技数组置为 0 */
}
for (int i = 0; i < n; i++) {
if (!visit[i]) {
DFS(G, i);
}
}
}3.2 图的广度优先搜索
3.2.1 原则
从图中某个指定的顶点 v 出发,先访问顶点 v,然后依次访问顶点 v 的各个未被访问过的邻接点,然后又从这些邻接点出发,按照同样的规则访问它们的那些未被访问过的邻接点,如此下去,直到图中与 v 相通的所有顶点都被访问;若此时图中还有未被访问过的顶点,则从另一个未被访问过的顶点出发重复上述过程,直到遍历全图。
3.2 算法分析
- 采用邻接表存储该图:$O(n+e)$
- 采用邻接矩阵存储该图:$O(n^2)$
3.3 算法实现(邻接表结构)
ElemType queue[MAXN]; /* 队列结构 */
int front,rear;
void BFS(VLink G[], int v) {
printf("%d ",G[v].vertex); /* 访问结点 v */
visit[v] = 1; /* 顶点 v 对应的访问标记置为 1 */
front = rear = -1;
queue[++rear] = v; /* 顶点 v 入队 */
while (front != rear) {
v = queue[++front]; /* 退出队头元素,赋给 v */
ELink *p = G[v].link; /* p 赋值为顶点 v 的第一个边结点 */
while (p) {
if (!visit[p->adjvex]) {
printf("%d ",G[p->adjvex].vertex); /* 访问边结点指向的顶点 p->adjvex */
visit[p->adjvex] = 1; /* 当前访问的结点 p->adjvex 对应访问标记置为 1 */
queue[++rear] = p->adjvex; /* 当前访问的结点 p->adjvex 进队 */
}
p = p->next; /* 求顶点 v 的下一个边结点 */
}
}
}
/* BFS 主算法 */
void TRAVERSE_BFS(VLink G[], int n) {
for (int i = 0; i < MAXN; i++) {
visit[i] = 0; /* 标记数组置为 0 */
}
for (int i = 0; i < n; i++) {
if (!visit[i]) {
BFS(G, i);
}
}
}4.最小(代价)生成树、最短路径、AOV 网与拓扑排序的基本概念。
4.1 最小(代价)生成树
最小(代价)生成树:带权连通图中,总的权值之和最小的带权生成树为最小生成树。最小生成树也称最小代价生成树,或最小花费生成树。
4.1.1 最小生成树构建原则
- 只能利用图中的边来构造最小生成树;
- 只能使用、且仅能使用图中的 n-1 条边来连接图中的 n 个顶点;
- 不能使用图中产生回路的边。
4.1.2 普里姆(Prim)算法
4.1.2.1 算法描述
- 设 $G = (V,GE)$ 为具有 n 个顶点的带权连通图;$T = (U, TE)$ 为正在生成的最小生成树,初始时,$TE = 空,U = {v_1},v_1 \in V$。
- 依次在 G 中选择一条一个顶点仅在 V 中,另一个顶点在 U 中,并且权值最小的边加入集合 TE,同时将该边仅在 V 中的那个顶点加入集合U。 重复上述过程 n–1 次,使得 $U = V$,此时 T 为 G 的最小生成树。
4.1.2.2 算法实现
int G[110][110],vis[110],low[110],pre[110];
//G[][]存放图,vis[]表示Va(属于 MST 的集合)、Vb(不属于 MST 的集合)集合,low[] 表示生成树边长集合
//pre[i] 对应 low[i] 中所表示的最短边,记录当前点的父节点。pre[i] = j 表示 j 指向 i 的那条边。
void Prim(int N) {
memset(vis,0,sizeof(vis));
int ans = 0,pos = 1;//ans 记录 MST 大小,pos 记录加点位置。pre[i] = j 表示 j 指向 i 的那条边。
vis[pos] = 1; //
low[pos] = 0; //无意义
for(int i = 1; i <= N; i++) { //初始化
if(i != pos) {
low[i] = G[pos][i];
pre[i] = 1;
}
}
for(int i = 1; i < N; i++) { // 循环 N-1 次,每次加入一个点
int Min = 0xffffff0;
pos = 0;
for(int j = 1; j <= N; j++) { // 找出费用最小的点的话,那该节点连接所需费用一定最小
if(!vis[j] && low[j] < Min) {
Min = low[j];
pos = j;
}
}
if(pos == 0) {
return; // 没有点可以扩展,图 G 不连通,可用于判断联通
}
ans += Min; //添加边
vis[pos] = 1;
//维护 low 数组,以当前找到的新节点作为起点,更新各节点的最小费用
//否则上一行找到的最小值节点无法确定就是最小的,其包含了动态规划的思想
//对每个与 pos 点相邻的未遍历的点 j,更新到 j 点最近的点及距离
for(int j = 1; j <= N; j++) {
if(!vis[j] && low[j] > G[pos][j]) {
low[j] = G[pos][j];
pre[j] = pos;
}
}
}
printf("%d\n",ans);
}
// 调用主方法
int main(int argc, const char * argv[]) {
int N,w;
scanf("%d",&N);
for (int i = 1; i <= N; i++) {
for (int j = 1; j <= N; j++) {
scanf("%d",&w);
G[i][j] = w;
}
}
Prim(N);
}4.1.3 克鲁斯卡尔(Kruskal)算法
4.1.3.1 算法描述
从 G 中选择一条当前未选择过的、且边上的权值最小的边加入 TE,若加入 TE 后使得 T 未产生回路,则本次选择有效,如使得 T 产生回路,则本次选择无效,放弃本次选择的边。重复上述选择过程直到 TE 中包含了 n-1 条边,此时的 T 为 G 的最小生成树。
实现过程:
- 设一个有 n 个顶点的连通网络为 $G(V,E)$,最初先构造一个只有 n 个顶点,没有边的非连通图 $T = {V,空}$,图中每个顶点自成一格连通分量。
- 在E中选择一条具有最小权植的边时,若该边的两个顶点落在不同的连通分量上,则将此边加入到T中;否则,即这条边的两个顶点落到同一连通分量上,则将此边舍去(此后永不选用这条边),重新选择一条权植最小的边。
- 如此重复下去,直到所有顶点在同一连通分量上为止。
4.1.3.2 算法实现
using namespace std;
const int MAXN = 1010;
const int MAXM = 200020;
struct Edge { // 边结点结构
int from; // 边的起点
int to; // 边的终点
int w; // 权值
}Edges[MAXM];
int father[MAXN];
// 并查集:father[i] 为顶点 i 所在集合对应的树中的根结点
// 如果 father[i] 和 father[j] 相同,则说明顶点 i 和顶点 j 在同一个集合
// find: 找到顶点 x 所在的根结点
int find(int x) {
if(x != father[x])
father[x] = find(father[x]);
return father[x];
}
// 将边按权值排序
int cmp(Edge a,Edge b) {
if(a.w != b.w)
return a.w < b.w; //return a.w > b.w;求最大生成树
if(a.from != b.from)
return a.from < b.from;
return a.to < b.to;
}
int KRUSKAL(int N, int M) {
sort(Edges, Edges+M, cmp); // 先将边按权值排序
int ans = 0,count = 0; // count 表示合并的变数, ans 存放 MST 大小
for(int i = 0; i < M; i++)
{
int u = find(Edges[i].from);
int v = find(Edges[i].to);
if(u != v)
{
ans += Edges[i].w;
father[v] = u;
count++;
if(count == N-1)//合并了N-1条边,已经找到了最小生成树
break;
}
}
if(count == N-1) // 找到最小生成树
return ans;
else // 图不连通
return -1;
}
int main(int argc, const char * argv[]) {
int N,M,x,y,w;
scanf("%d%d",&N,&M);
//初始化及构图
for(int i = 1; i <= N; i++) {
father[i] = i;
}
int Sum = 0;
for(int i = 0; i < M; i++) {
scanf("%d%d%d",&x,&y,&w);
Edges[i].from = x;
Edges[i].to = y;
Edges[i].w = w;
Sum += w;
}
int ans = KRUSKAL(N,M);
printf("%d\n",ans);
return 0;
}4.2 最短路径
4.2.1 最短路径定义
- 路径长度:
- 不带权的图:路径上所经过的边的数目。
- 带权的图:路径上所经过的边上的权值之和。
- 最短路径:
- 所有带权路径中长度最短的一条路径,其路径长度成为最短路径长度(最短距离)。
4.2.2 单源最短路径
- 所有带权路径中长度最短的一条路径,其路径长度成为最短路径长度(最短距离)。
- 单源最短路径:
- 从源点 v(出发点)到图中其他 n-1 个顶点(目的地)之间的最短路径问题。
4.2.2.1 所需数据结构:
- 图的存储:以 1~n 分别代表 n 个顶点,采用邻接矩阵存储该图,有:
$Map[i][j] =\begin{cases} w_{ij}, & 当顶点 v_i 到顶点 v_j 有边,且权为W_{ij} \ \infty, & 当顶点v i 到顶点v j 无边时 \ 0, & 当 v_i = v_j 时 \ \end{cases}$ - 设置一个标志数组 vis[0..n-1] 记录源点 v 到图中哪些顶点的最短路径已经找到。有:
$vis[i] = \begin{cases} 1,& 表示源点到顶点 i 的最短路径已经找到 \ 0,& 表示源点到顶点 i 的最短路径尚未找到 \ \end{cases}$
初始时, $vis[v] = 1,vis[i] = 0 (i = 0,1,…,n-1,i \neq v)$ - 设置数组 $dist[0..n-1]$ 分别记录源点 v 到图中各顶点的最短路径的路径长度, 其中,dist[i] 记录源点到顶点 i 的最短路径的长度。
初始时,dist 数组的值为邻接矩阵第 v 行的 n 个元素值。$ (i = 0,1,…,n-1)$ - 设置数组 $pre[0..n-1]$ 分别记录源点 v 到图中各顶点的最短路径所经过的顶点序列, 其中,pre[i] 记录源点到顶点 i 的路径。
初始时,$pre[i] = {v}, (i = 0,1,…,n-1)$
4.2.2.2 算法描述
- 确定 dist、vis、pre 三个数组的初值。
- 利用 vis 数组与 dist 数组在那些尚未找到最短路径的顶点中确定一个与源点 v 最近的顶点 u,并置 vis[u] 为 1,同时将顶点 u 加入 pre[u]。
- 根据顶点 u 修改源点到所有尚未找到最短路径的顶点的路径长度。 即:
- 将源点 v 到顶点 u 的最短路径长度分别加到源点 v 通过顶点 u 可以直接到达、且尚未找到最短路径那些的顶点的路径长度上。若加后的长度小于原来 v 到某顶点 r 的路径长度,则用加后的长度替换原来的长度,否则不替换。
- 若替换,将源点 v 到顶点 u 的路径(最短路径)上经过的所有顶点替换 pre[r]。
- 重复上述过程的第 2 至第 3 步 n–1 次。
4.2.2.3 算法实现
#include <iostream>
#include <algorithm>
#include <cstdio>
#include <cstring>
using namespace std;
const int MAXN = 110;
const int INF = 0xffffff;
int map[MAXN][MAXN],pre[MAXN],dist[MAXN];
bool vis[MAXN];
//map[][] 来存储图,pre[] 来保存结点前驱、源点、终点
//dist[i] 为源点 s 到节点 i 的最短距离
//vis[i] 记录点 i 是否属于集合 Va
void Dijkstra(int N,int s) {
int Min;
for(int i = 1; i <= N; ++i) { //初始化
vis[i] = false;
if(i != s) {
dist[i] = map[s][i];
pre[i] = s;
}
}
dist[s] = 0;
vis[s] = true;
for(int i = 1; i <= N-1; ++i) { //循环 N-1 次,求源点 s 到其他 N-1 个点最短路径
Min = INF;
int k = 0;
for(int j = 1; j <= N; ++j) { //在 Vb 中的点中取一个 s 到其距离最小的点 k
if(!vis[j] && dist[j] < Min) {
Min = dist[j];
k = j;
}
}
if(k == 0) //如果没有点可以扩展,即剩余的点不可达,返回
return;
vis[k] = true; //将 k 从 Vb 中除去,加入到 Va 中
for(int j = 1; j <= N; ++j) { //对于每个与 k 相邻的在 Vb 中的点 j,更新 s 到 j 的最短距离
if(!vis[j] && map[k][j] != INF && dist[j] > dist[k] + map[k][j]) {
dist[j] = dist[k] + map[k][j];
pre[j] = k;
}
}
}
}
int main(int argc, const char * argv[]) {
int N,M,a,b,w;
while(~scanf("%d%d",&N,&M) && (N||M)) {
//初始化注意
for(int i = 1; i <= N; ++i) {
for(int j = 1; j <= N; ++j) {
map[i][j] = INF;
}
}
for (int i = 1; i <= N; i++) {
dist[i] = INF;
pre[i] = 0;
}
for(int i = 0; i < M; ++i) {
scanf("%d%d%d",&a,&b,&w);
map[a][b] = map[b][a] = w;
}
Dijkstra(N,1);
printf("%d\n",dist[N]);
}
return 0;
}4.3 AOV 网与拓扑排序
4.3.1 AOV 网
- 以顶点表示活动,以有向边表示活动之间的优先关系的有向图称为 AOV 网。
- 在 AOV 网中,若顶点 i 到顶点 j 之间有路径,则称顶点 i 为顶点 j 的前驱,顶点 j 为顶点 i 的后继;
- 若顶点 i 到顶点 j 之间为一条有向边,则 称顶点 i 为顶点 j 的直接前驱, 顶点 j 为顶点 i 的直接后继。
4.3.2 拓扑排序
检查 AOV 网是否存在回路的方法是对 AOV 网进行拓扑排序,即构造一个顶点序列,使得该顶点序列满足下列条件:
- 若在 AOV 网中,顶点 i 优先于顶点 j,则在该序列中也是顶点 i 优先于顶点 j ;
- 若在 AOV 网中,顶点 i 与顶点 j 之间不存在优先关系,则在该序列中建立它们的优先关系,即顶点 i 优先于顶点 j,或顶点 j 优先于顶点 i;
- 若能够构造出拓扑序列,则拓扑序列包含 AOV 网的全部顶点,说明 AOV 网中没有回路。
4.3.3 拓扑排序方法
- 从 AOV 网中任选择一个没有前驱的顶点;
- 从 AOV 网中去掉该顶点以及以该顶点为出发点的所有边;
- 重复上述过程,直到网中的所有顶点都被去掉(AOV 网中无回路),或者网中还有顶点,但不存在入度为 0 的顶点(AOV 网中存在回路)。
4.3.4 拓扑排序算法描述
- 首先建立一个入度为 0 的顶点堆栈,将网中所有入度为 0 的顶点分别进栈。
- 当堆栈不空时,反复执行以下动作:
- 从顶点栈中退出一个顶点,并输出它;
- 从 AOV 网中删去该顶点以及以它发出的所有边,并同时分别将这些边的终点的入度减1;
- 若此时边的终点的入度为 0,则将该顶点进栈;
- 若输出的顶点个数少于 AOV 网中的顶点个数,则报告网中存在有向回路,否则,说明该网中不存在回路。
4.3.5 拓扑排序算法实现
书上代码:(利用 indegree 数组设置了一个链式结构的堆栈,将所有入度为 0 的顶点链接在一起)
typedef struct edge {
int adjvex;
int weight;
struct edge *next;
}ELink;
typedef struct ver {
int indegree;
int vertex;
ELink *link;
}TopoVLink;
void TopoSort(TopoVLink G[], int n) {
ELink *p;
int top = -1;
for (int i = 0; i < n; i++) { /* 堆栈初始化 */
if (G[i].indegree == 0) { /* 依次将入度为 0 的顶点压入堆栈中,top 表示栈顶元素 */
G[i].indegree = top;
top = i;
}
}
for (int i = 0; i < n; i++) { /* 进行拓扑排序 */
if (top == -1) {
printf("\n 网中存在回路!");
break;
} else {
int j = top;
top = G[top].indegree; /* 退出栈顶元素 */
printf("%d",G[j].vertex); /* 输出栈顶元素 */
p = G[j].link;
while (p != NULL) {
int k = p->adjvex; /* "删除"一条由 j 发出的边 */
G[k].indegree--; /* 当前输出的邻接点的入度减 1 */
if (G[k].indegree == 0) { /* 新的入度为 0 的顶点压入堆栈 */
G[k].indegree = top;
top = k;
}
p = p->next; /* 找到下一个邻接点(边结点) */
}
}
}
}4.3.6 测试给定序列是否是该有向图的一个拓扑序列
4.3.6.1算法思想
依次从序列中取一个元素(顶点)。首先在邻接表的顶点结点中找到该顶点,然后判断该顶点的入度是否为 0。若入度不为 0,则说明给定序列不是 G 的拓扑排序,算法结束(存在回路);若入度为 0,则说明当前所取得的顶点是拓扑序列中的一个顶点(若存在这样的拓扑序列的话),同时一次将以该顶点为起始点发出的边所对应的所有终点的入度减 1;然后取序列的下一个顶点,重复上述过程。直到序列中所有元素都已处理。
4.3.6.2 算法实现
// 给定的顶点序列存放在 V[] 中
int TOPO_TEST(TopoVLink G[], ElemType V[], int n) {
ELink *p;
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if (G[j].vertex == V[i]) { /* 若顶点 V[i] 是 G 中的顶点 */
if (G[j].indegree != 0) { /* 若顶点 V[i] 的入度不为 0 */
return 0; /* 序列不是 G 的拓扑序列 */
}
p = G[j].link; /* 若顶点 V[i] 的入度为 0 */
while (p != NULL) {
G[p->adjvex].indegree--; /* 相关顶点入度减 1 */
p = p->next;
}
break; /* 测试序列的下一个顶点 */
}
}
}
return 1; /* 序列为 G 的拓扑序列 */
}




柚子
?